 torch.js
torch.js
 torch.js
torch.jsWebGPU-accelerated deep learning. TypeScript-first.
import torch from '@torchjsorg/torch.js';
// Define a simple neural network
const model = new torch.nn.Sequential(
new torch.nn.Linear(784, 128),
new torch.nn.ReLU(),
new torch.nn.Linear(128, 10)
);
// Load data and train
const { images, labels } = await loadMNIST();
const optimizer = new torch.optim.Adam(model.parameters());
for (let epoch = 0; epoch < 10; epoch++) {
const output = model.forward(images);
const loss = torch.nn.functional.crossEntropyLoss(output, labels);
optimizer.zeroGrad();
loss.backward();
optimizer.step();
}const x = torch.zeros(2, 3, 4); // Tensor<[2, 3, 4]>
const y = torch.randn(4, 5); // Tensor<[4, 5]>
// Compile-time shape checking
const result = x.matmul(y); // Tensor<[2, 3, 5]> ✓
// Errors caught at compile time, not runtime
const bad = x.matmul(torch.randn(10, 10));
// ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
// Error: Cannot multiply [2,3,4] × [10,10]
// Autocomplete knows your tensor's shape
result.at(0, 1, 2); // Works
result.at(0, 1, 10); // Error: index 10 out of boundsconst data = torch.randn(10, 20, 30);
// Single element
data.at(0, 5, 10); // Scalar
// Slice ranges [start, end]
data.at([2, 5], ':', ':'); // data[2:5, :, :]
// Negative indexing
data.at(-1, ':', ':'); // Last along dim 0
data.at(':', ':', [-5, null]); // Last 5 along dim 2
// Step slicing [start, end, step]
data.at([0, 10, 2], ':', ':'); // Every 2nd from 0-10
// Ellipsis
data.at('...', -1); // data[..., -1]const a = torch.randn(2, 3);
const b = torch.randn(3, 4);
const c = torch.einsum('ij,jk->ik', a, b);
// ^? Tensor<[2, 4]>
// Type-safe einops - readable patterns
const images = torch.randn(32, 3, 224, 224);
const flat = einops.rearrange(images, 'b c h w -> b (c h w)');
// ^? Tensor<[32, 150528]>
// Errors caught at compile time
const bad = torch.einsum('ij,jk->ik', a, torch.randn(5, 4));
// ^? Error: Einsum index mismatch 'j': 3 vs 5import { $ } from '@torchjsorg/torch.js';
// Write fast code that is easy to read and optimize
const result = $(`sigmoid(x @ w + b)`)({ x, w, b });
// Scaled dot-product attention
function attention(Q, K, V, scale) {
const scores = $(`Q @ mT(K) / ${scale}`)({ Q, K });
return $(`softmax(scores, -1) @ V`)({ scores, V });
}
// Built-in RPN mode for stack-based execution
const rpn = $.r(`x w @ b + relu`)({ x, w, b });| Feature | torch.js | TFJS | ml5 | ONNX |
|---|---|---|---|---|
| Native WebGPU | Yes | Plugin | No | Yes |
| Shape Type Safety | Built-in | Partial | None | None |
| Einsum Types | Yes | No | No | No |
| Autograd Sync | Yes | N/A | N/A | N/A |
Fast WebGPU Performance
torch.js isn’t a wrapper. It’s built from the ground up to leverage raw WebGPU compute shaders for every operation, providing PyTorch compatibility with native TypeScript type safety.
Built-in Ecosystem
Everything you need to build, visualize, and share.
From Tensors to Insights
Beautiful, real-time visualizations for every step of your workflow.
Understand Your Models
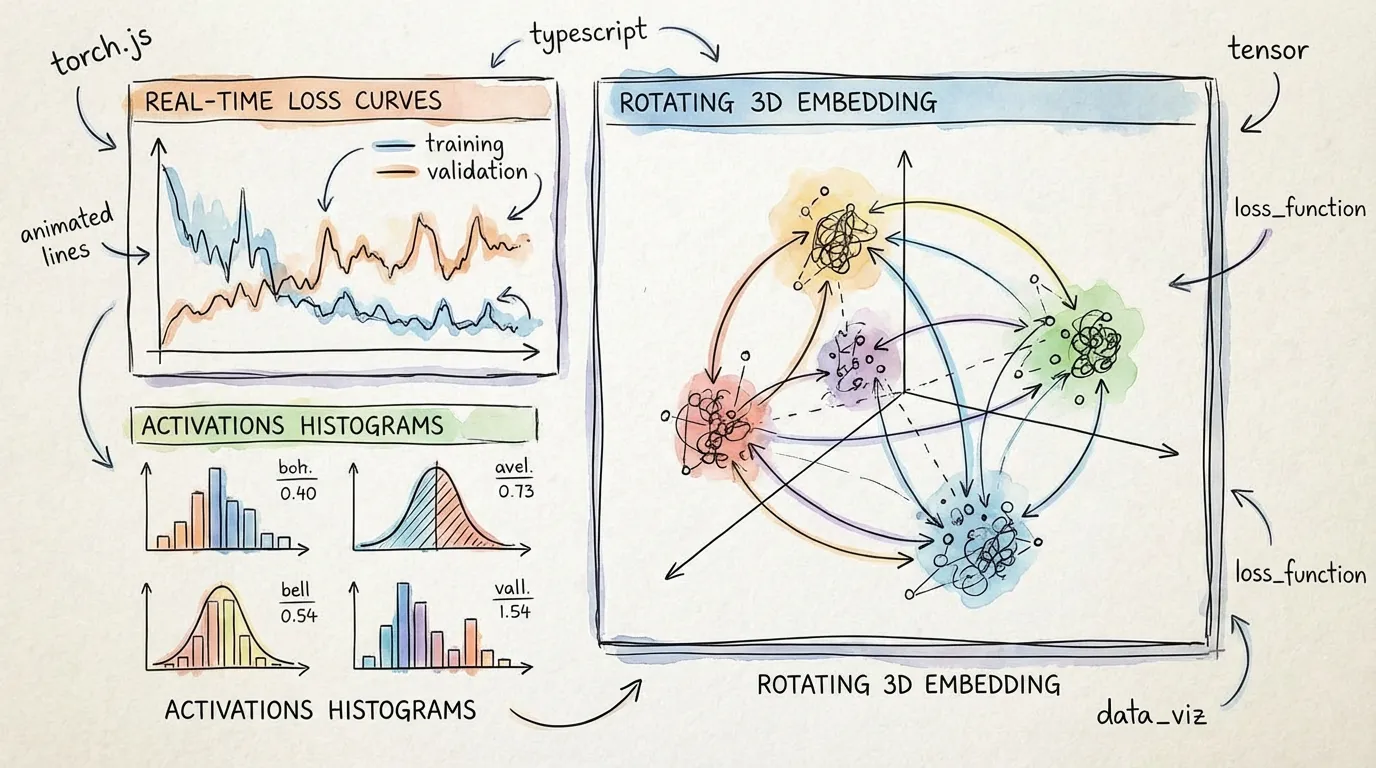
torch.js comes with over 60+ specialized components for visualizing weights, activations, and training dynamics in real-time.
Attention Visualization
Interactive attention pattern viewers show head-by-head weights.
Activation Inspection
Pause at any layer and inspect real-time activation distributions.
Gradient Flow
Visualize gradients and identify vanishing or exploding issues.
Ready to build browser-based AI?
Start with our interactive playground or read the documentation.
Recent Activity
Real-time updates from the community